
7. 데이터 처리
7.3. 마킹과 데이터 관계
Spotfire에서 마킹(Marking)은
데이터 테이블에서 선택한 로우를 표시하는 것을 말합니다. 예를 들면 시각화 차트에서 A종목에 해당하는 로우들을 선택하는 것을 말합니다. 이처럼 마킹은
의미나 모습은 매우 단순합니다. 하지만 마킹을 다른 데이터 제한(Data
limit), 데이터 관계(Data relation) 등과 같이 사용하면 드릴다운 분석을
통해 통찰을 제공하는 분석이 가능합니다. 마킹과 이와 관련된 기능과 함께 드릴다운 분석까지 적용하는
방법을 소개합니다.
l 7.3.1. 마킹
앞서 소개했듯이 마킹은 선택한
데이터를 표시하는 기능을 말합니다. Spotfire를 다루면서 알게 모르게 마킹을 사용해 왔습니다. 차트에서 데이터를 선택하면 해당 데이터만 하이라이트 된다던가 표에서는 바탕색이 표시되는 모습들이 마킹이 표시된
것입니다.

차트에서의 마킹과 표에서의
마킹
n 마킹 설정 경로
Spotfire에서는 기본적으로
'marking' 이라는 이름을 가진 마킹 하나가 존재하며, 기본 색상은 파란색으로 표시됩니다. 마킹의 추가 생성과 이름변경, 삭제는 아래의 경로에서 설정할 수
있습니다.
위치: 파일 - 문서 속성 - 마킹 / 차트
속성 - 데이터 탭 - 마킹 - 신규
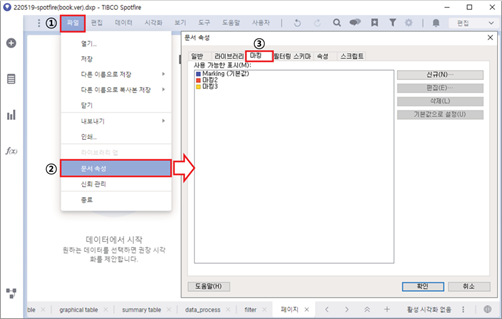
마킹 설정 위치
차트 속성의 데이터 탭에서는
마킹의 생성만 가능하기 때문에 여러 개의 마킹을 사용하고 관리하려면 파일의 문서 속성에서 마킹을 관리하는 편이 좋습니다.
n 마킹과 데이터 제한의 적용
마킹은 이름으로 구별되는
여러 개의 마킹을 생성할 수 있습니다. 또한 동일한 이름의 마킹은 시각화 차트와 관계없이 공유됩니다. 즉 하나의 시각화 차트에서 마킹하면(데이터를 선택하면) 다른 시각화 차트에서도 마킹이 표시됩니다. 시각화 차트에서 마킹의
선택은 차트 속성의 데이터 탭에서 선택할 수 있습니다. 한편, 데이터
제한은 차트에서 데이터의 일부만 보여주도록 제한 하는 기능입니다. 의미 상으로 필터와 유사합니다. 하지만 필터와의 차이는 필터 조건으로 적용하는 것이 아닌 마킹된 데이터만을 표현해 줍니다. 가령 '마커1'이라는
마킹으로 데이터 제한을 지정하면 해당 차트는 마커1로 선택된 로우만을 차트에 그려줍니다. 데이터 제한은 차트 속성에서 데이터 탭에서 설정할 수 있습니다.
위치: 차트 속성 - 데이터 탭 - 마킹 선택 / 차트
속성 - 데이터 탭 - 데이터 제한

마킹 설정 위치
위 그림을 자세히 이해할
필요가 있습니다. 왼쪽의 시각화 차트1에서는 '마커1'이라는 이름의 마킹을 사용하고 있습니다. 데이터 선택 시, 선택된 데이터는
'마커1'이라는 마킹으로 표시되고, 이 마킹은
시각화 차트와 무관하게 다른 시각화 차트2에서도 선택됩니다. 하지만
시각화 차트 2에는 데이터 제한이 걸려 있습니다. '마커1'만을 사용하여 차트를 구성하도록 제한이 걸려있기 때문에 '마커1'을 데이터로 하는 시각화 차트2로 표시됩니다. 즉, 차트2는 차트1에서 선택된 데이터를 세부적인 내용을 보여주는 차트라고 설명할 수 있습니다.
l 7.3.2. 데이터 관계
데이터 관계(Data relation)은 데이터 테이블 간에 마킹을 공유하는 기능입니다. 마킹은
하나의 데이터 테이블에 적용 가능한 기능입니다. 데이터 관계는 두 데이터 테이블 사이에 값이 동일한
컬럼을 지정하여 컬럼 값이 동일하면 동일한 마킹을 부여하는 기능입니다. 즉, ‘데이터 테이블 A’의 ‘컬럼 a‘와 ‘데이터 테이블 B’의 ‘컬럼 b’를 데이터 관계를 설정해두면, ‘컬럼 a’의 컬럼 값 ‘aa’ 선택 시, ‘컬럼 b’의 컬럼 값 ‘aa’ 값이 모두 선택됩니다. 데이터
테이블끼리 합치는 병합(Merge)와 유사하지만, 데이터
관계는 겉으로 합쳐지는 모습은 보여주지 않습니다. 또한 데이터 관계에서 공유하는 것은 마킹 밖에 없기
때문에 마킹과 필수적으로 함께 사용됩니다. 데이터 관계는 데이터 테이블 속성에서 설정할 수 있습니다.
위치: 데이터 - 데이터 테이블 속성 - 관계 - 관계
관리

데이터 관계 설정하기
위 그림에서 설정 된 데이터
관계는 다음과 같습니다. 데이터 테이블 Ticker_info의
컬럼 Ticker와 데이터 테이블 company_add_info의
컬럼 Ticker가 데이터 관계로 설정되어 있습니다. 차트에
표시되는 모습을 보면 아래와 같이 표시 됩니다.

데이터 관계 설정 후, 차트에서 표시되는 모습
위 그림은 데이터 관계 설정
후, 차트에서 표시되는 모습을 보여줍니다. 먼저 데이터 테이블
Ticker_info에서 A 로우 선택 시, 로우의 Ticker컬럼 값 A와
동일한 데이터 테이블 Company_add_info의 Ticker 컬럼의
로우가 선택 됩니다. 그래서 Ticker A를 가지는 로우가
표시됩니다. 반면, 데이터 테이블 Company_add_info에서 A 로우 선택 시, 로우 Ticker 컬럼 값 A와
동일한 데이터 테이블 Ticker_info의 Ticker 컬럼의
로우가 선택 됩니다. 즉, 데이터 관계가 설정된 대로 동일한
컬럼 값을 가지는 것들이 선택 됩니다.
l 7.3.3. 드릴 다운 분석
드릴 다운 분석(Drill-down analysis)은 일반적으로 문제를 해결하기 위해서 문제를 여러 하위 계층으로 분할하고
분할된 문제에 대한 해결방법 제시, 구조 파악 등을 통해 최종적으로 문제의 구조와 해결방법을 총합하는
분석 기법입니다. 드릴다운 분석을 Spotfire에서는 마킹과
데이터 제한, 그리고 데이터 관계 기능으로 구현 할 수 있습니다. 드릴다운
분석을 위한 문제와 요구사항은 아래와 같습니다.
- 데이터 테이블
Company_add_info를 사용하여 Ticker의
Market cap 순위 별 EPS와 Net income의
관계를 설명하라.
이 문제는 복잡한 문제 같아
보이지만, 작은 부분들로 나누면, 순위 별 Ticker의 EPS와 Net
income 관계를 모두 살펴보고 합치면 되는, 드릴다운을 적용할 수 있는 문제입니다. 문제를 풀기 위해 마킹, 데이터 제한, 그리고 데이터 관계를 사용해 풀이 하겠습니다.

드릴다운 분석 적용 문제
풀이
위 그림과 같이 데이터 테이블을
각각 설정합니다. 마킹과 데이터 제한, 그리고 데이터 관계를
설정한 후에는 Company_add_info를 표로 그리고,
Ticker_info를 EPS와 당기순이익을 보여주는 산점도로 그립니다. 이제 Company_add_info를 Ticker 별로 마킹해 봅니다. 6 종목을 하나씩 마킹했을 때의 모습을
위 그림에서 표시하고 있습니다. 자세히 보면 Company_add_info에서
마킹1이 선택되고, 데이터 관계에 의해 Company_add_info와 Ticker_info가 연결됩니다. 그리고 Ticker_info에서 마킹1로 데이터 제한이 걸려 해당 Ticker에 대한 EPS와 Net income 차트를 그리고 있습니다.
7.4. 데이터 캔버스
데이터 캔버스(Data canvas)는 하나의 데이터 테이블에 진행한 모든 처리를 이미지화하여 보여주는 기능입니다. 따라서 데이터 캔버스를 보면 데이터 테이블의 시작부터 끝까지 이루어진 변환의 종류와 순서를 빠르고 정확하게
파악할 수 있습니다. Spotfire에서 하는 작업들이 간단한 일회성으로 차트를 그리고 끝나는 업무라면
중간 과정과 변환들을 복습하거나 점검할 필요는 없습니다. 하지만
Spotfire를 이용해 반복되는 작업을 수행하거나 복잡한 데이터 구조를 가지고 작업할 때에는 데이터 처리 종류와 순서 그리고 재현성이
중요합니다. Spotfire에서는 저장 된 파일을 불러올 때는 사용자가 파일을 만들 때 실행했던 모든
기능들, 데이터 로드부터 최종 결과까지의 모든 변환과 순서를
Spotfire 내부에서 동일하게 진행합니다. 따라서 로드하는 데이터의 일부 컬럼이 변하던가, 변환 종류나 순서가 틀어지게 되면 오류가 발생하고, 최종 결과는
산출되지 않습니다. 따라서 데이터 캔버스를 사용하여 데이터 테이블에 실행되는 변환의 종류와 순서를 점검하는
것이 좋습니다.
l 7.4.1. 데이터 변환 종류
데이터 캔버스 요소를 설명하기
전에, 데이터 테이블의 변환은 데이터 테이블 내 변환과 데이터 테이블 간 변환으로 나눌 수 있습니다. 데이터 테이블 내 변환은 다른 데이터 테이블의 개입없이 대상 데이터 테이블 내에서 실행되는 변환을 뜻합니다. 새로운 컬럼을 생성하거나 로우를 삭제, 그리고 피벗, 언피벗 등의 변환이 있습니다. 반면, 데이터 테이블 간 변환은 여러 개의 데이터 테이블이 관여하여 변환한 경우를 말합니다. 컬럼 병합이나 로우 병합이 있습니다. Spotfire에서는 두 변환을
구별하기 때문에 데이터 캔버스에서 표시되는 모습이나 변환을 적용하는 방법이 다릅니다.
l 7.4.2. 데이터 캔버스 모습
데이터 캔버스의 모습은 위
그림과 같습니다. 화면의 좌측 상단에는 데이터 테이블을 선택할 수 있습니다. 데이터 캔버스는 하나의 데이터 테이블을 기준으로 데이터 처리 과정을 보여주기 때문에 보고 싶은 데이터 테이블을
여기서 선택해 줍니다. 데이터 테이블 선택 옆에는 이름변경, 데이터
대체, 삭제와 같은 데이터 테이블에 대한 처리 기능이 있습니다. 화면
중앙에는 메인 화면이 위치하여 데이터 테이블의 처리 과정을 시각화해 보여줍니다. 화면 좌측 하단에는
메인 화면에서 선택한 데이터 테이블에서 사용한 변환을 순서대로 보여줍니다.
위치: 데이터 캔버스 / 데이터 - 데이터 캔버스

데이터 캔버스 화면
데이터 테이블을 의미하는
사각형 박스 단위로 메인 화면이 구성됩니다. 왼쪽에는 데이터 소스(Data
source)에서 데이터 테이블을 로드하는 것에서부터 오른쪽으로 화살표가 진행되면서 데이터 테이블 내 변환, 데이터 데이터 간 변환 등이 실행되고, 마지막으로 최종 데이터 테이블이
완성됩니다. 일련의 데이터 처리 과정들을 통해 분석에 사용된 최종 데이터 테이블을 작성하는 방법에 대한
통찰을 얻을 수 있습니다. 화면 우측 하단에는 선택한 데이터 테이블의 미리보기를 제공합니다. 선택한 데이터 테이블 또는 변환 후의 모습을 보여주기 때문에 메인화면에서 확인하고 싶은 데이터 테이블을 선택하거나, 변환화면에서 확인하고 싶은 변환을 선택하면 됩니다. 마지막으로 우측
최하단에는 로우와 컬럼 정보를 제공하여 미리보기로 가늠하기 어려운 데이터테이블의 전체적인 크기에 대한 정보를 제공합니다.
l 7.4.3. 데이터 캔버스 요소

데이터 캔버스 요소들
위 표는 메인 화면에서 사용되는
요소들에 대한 설명입니다.
- 데이터 테이블: 사각형
박스는 데이터 테이블을 나타냅니다. 사각형 박스는 데이터 테이블 내 변환에서는 동일한 사각형 박스가
유지되고, 데이터 테이블 간 변환이 사용되었을 때 새로 지정됩니다.
- 최종 데이터 테이블: 데이터
처리를 모두 완료한 최종 데이터 테이블은 가로가 긴 직사각형 형태를 하고 있습니다. 메인 화면에서 왼쪽에서
오른쪽으로 순서가 진행되므로 이 최종 데이터 테이블은 항상 오른쪽에 위치합니다.
- 순서: 데이터 처리
과정은 사각형 박스를 연결하는 화살표로 표시됩니다.
- 데이터 테이블 간 변환: 데이터
테이블 간 변환을 위해서는 다른 데이터 테이블을 불러오는 것이 필요합니다. 다른 데이터 테이블을 불러오는
것은 화살표 내에는 (+) 아이콘을 통해 가능하며, 데이터
테이블 간 변환에 대한 설정을 할수 있는 윈도우 창이 뜹니다.
- 데이터 테이블 내 변환: 데이터
테이블 내 변환은 사각형 박스 변경없이 내부에 표시됩니다. 내 변환 적용 개수는 사각형 박스 우상단에
숫자로 표시됩니다. 내 변환의 자세한 내용은 메인 화면 하단의 변환 화면에서 구체적인 변환 종류와 순서가
표시됩니다. 내 변환 생성은 변환 화면에서 변환 사이 또는 끝에
(+) 아이콘을 누르면 추가가 되고, 편집은 기어 아이콘을 누르면 편집 가능한 윈도우 창이
뜹니다. 삭제는 휴지통 아이콘을 누르면 삭제가 가능합니다.
- 삭제, 설정: 사각형 박스의 좌상단에는 휴지통 모양의 아이콘을 통해 삭제가 가능합니다. 또한
사각형 박스 하단의 기어 모양의 아이콘을 통해 사각형 박스의 설정 변경이 가능합니다.
Spotfire의 데이터 캔버스는 데이터 처리 과정을 보여주고 추가, 삭제, 편집이 가능한 매우 좋은 기능입니다. 하지만 한 가지 아쉬운 점은 데이터 캔버스의 단위가 데이터 테이블이라는 것입니다. 데이터 테이블을 여러 개를 사용하는 경우 전체 데이터 테이블 간의 관계를 보여주는 기능이 필요한 경우가 있기
때문에, 이 기능이 있었다면 폭 넓은 이해와 활용이 가능했을 것으로 예상합니다.

![[spotfire] 8. 기타 - 각종 설정, 부가기능, 팁](https://blogger.googleusercontent.com/img/a/AVvXsEjyjCAZP1U4DoDLM_ieWihypucu-Nw2IYT8jY5sDLM7YxoT0vWXw3wGdrxFTh41BDCkkS9wP1hJthIKwsbCUlYKCKdgMBs6e1rIoSY_18LjwvqVPKgHtJYc0O2Tu6c1tViADfQpidOS1gsFeRqxDBQCWldVPrWsR0xj4KzULu_miRcAJYLSySKtYyz-=w100)
![[spotfire advance] 4.3. spotfire의 HTML 활용 - text area 표 그리기, 막대 그리기](https://4.bp.blogspot.com/-O3EpVMWcoKw/WxY6-6I4--I/AAAAAAAAB2s/KzC0FqUQtkMdw7VzT6oOR_8vbZO6EJc-ACK4BGAYYCw/w100/nth.png)
![[spotfire] 5. 차트 그리기 ② - 차트 속성, 변경, 수정](https://blogger.googleusercontent.com/img/a/AVvXsEg3TKSfzFEpWb7xTOCrx2CaRa2lluSrZSmAOa1bxVWIZ8c8ZUsIKXcl89eoqKWUNmfJVnYJdGO5XQLyfl126Q_Zv0svmMIMBk7gAiNf1Lwj7Gf7MpgxsqBAvgbjhOZ32FriPg7JIO6LF8iSPhyO5ZyGVcojDs8jA2Bc3XXOeBNwwy3UObxhPGRgp_OB=w100)
0 댓글