
7. 데이터 처리
7.5. 데이터 테이블 내 변환
본격적으로 데이터 처리하는
기능과 방법들을 소개하고자 합니다. Spotfire에서는 데이터 변환(Data
transform)이라는 이름으로 데이터 테이블 내 변환 기능을 제공합니다. 데이터 변환은
데이터 캔버스의 변환 화면에서 (+) 아이콘을 통해 실행할 수 있습니다. 데이터 변환의 종류는 아래와 같습니다.

Spotfire 에서 제공하는 데이터 변환
- 값 바꾸기(Replace
value)
- 데이터 함수(Data
function)
- 데이터 형식 변경(Change
data types)
- 새컬럼 계산(Calculated
new column)
- 언피벗(Unpivot)
- 정규화(Normalization)
- 컬럼 계산 및 바꾸기(Calculated
and replace column)
- 컬럼 이름 변경(Change
column names)
- 컬럼 제외(Exclude
columns)
- 특정 값 바꾸기(Replace
specific value)
- 피벗(Pivot)
- 행 필터링(Filter
rows)
여러가지 데이터 변환이 있지만, 본질적으로는 아래의 4가지 종류로 분류 할 수 있습니다.
1. 새로 만들거나(새컬럼계산, 데이터 함수, 정규화)
2. 수정하거나(컬럼 계산
및 바꾸기, 컬럼 이름 변경, 데이터 형식 변경, 값 바꾸기, 특정 값 바꾸기)
3. 삭제하거나(컬럼 제외, 행 필터링)
4. 피벗, 언피벗 변환(피벗, 언비벗)
이 4가지 종류 별로 하나씩 데이터 변환 방법을 설명 드리겠습니다. 데이터
변환은 자주 사용하는 변환이 정해져 있고, 설정 창의 모습은 거의 비슷한 모습을 하고 있기 때문에 어렵지
않게 배울 수 있습니다.
l 7.5.1. 새 컬럼 계산
새 컬럼 계산(Calculated new column)은 가지고 있는 데이터 테이블 컬럼 이외의 새로운 컬럼을 생성할 때 사용하는
기능입니다. 새로운 컬럼 생성은 해당 데이터 테이블 내의 컬럼 값을 기반으로 만들 수 있습니다. 새 컬럼 계산은 매우 자주 활용되는 변환입니다. 또한 변환을 수행하는
설정 창은 다른 변환의 설정 창과 유사한 모습을 하고 있기 때문에, 새 컬럼 계산 변환을 확실하게 아는
것이 좋습니다. 새 컬럼 계산에 위치는 아래와 같습니다.
위치: 데이터 캔버스 - (+) 아이콘 - 데이터 변환
- 새 컬럼 계산 / 데이터 - 계산된 컬럼
추가

새 컬럼 계산의 접근 위치
두 가지 실행 방법의 이름이
약간 다르지만, 데이터 테이블에 컬럼을 추가한다는 기능은 동일합니다.
하지만 데이터 캔버스를 통해 변환하는 방법이 데이터 처리 과정을 구성함에 있어 더 체계적이고 관리하기 쉽습니다.

새 컬럼 계산의 설정 창
모습
위 그림은 새 컬럼 계산의
설정 창의 모습과 각 구역의 기능을 보여줍니다. 설정 창의 최상단에는
3개의 구역이 있습니다. 왼쪽은 데이터 테이블에 속한 컬럼들이 나열됩니다. 중간에는 사용할 수 있는 프로퍼티들이 나옵니다. 오른쪽에는 사용할
수 있는 함수들이 나옵니다. 이렇게 컬럼, 프로퍼티, 함수들을 아래쪽의 표현식 부분에서 사용할 수 있습니다. 표현식은
새 컬럼 값을 만들기 위한 식입니다. Excel에서 함수를 사용해서 셀을 채우듯이 Spotfire에서는 컬럼 이름, 함수 등을 사용한 표현식을 사용해서
새 컬럼을 생성합니다. 표현식 아래 부분에서는 이전에 활용한 표현식을 보여줍니다. 또한 새로 생성되는 컬럼의 이름을 지정하는 부분도 있고 표현식으로 생성되는 컬럼의 값과 형식을 미리보기 하는
부분도 있습니다.
n 표현식 만들기
표현식에 사용되는 함수들을
살펴보면 어딘가 익숙한 모습이라는 것을 느낄 수 있습니다. 평소
Excel을 많이 사용하셨다면 Excel의 함수와 비슷하다고 생각할 수도 있습니다. 또한 DBMS나 SQL을
사용하셨다면 SQL 함수와 비슷하다고 생각할 수 있습니다. 실제로 Excel이나 SQL의 함수와
Spotfire 함수는 이름이나 용법이 거의 동일합니다. 때문에 큰 어려움 없이 사용하실
수 있을 것입니다. 설령 사용법을 모르더라도 오른쪽 함수 부분에서 종류와 설명, 사용법 등이 자세히 나옵니다. 자주 사용하는 함수를 소개 합니다.
- 통계함수: Avg, Med,
Max, Min..
- 변환함수: Boolean,
Date, DateTime, Integer, String...
- 수학함수: Cos, Sin,
Tan, Log, Mod, PI, Round, Power...
- 문자함수: Split,
Substring, Left, Right, Len
- 순위함수: Rank,
DenseRank
- 논리함수: if, case
when, Is Null,
- 날짜함수: Today,
DateDiff, Year, Month, Week
- 키워드: AS, NEST,
OVER
n 변환 함수 사용하기
변환 함수는 사용방법은 크게
어렵지 않습니다. 함수명을 바꿔줄 형식으로 작성하기만 하면 되지만, 날짜로
변환하는 DateTime나 Date 사용 시에는 어떻게 넣어야
되는지 알고 계셔야 됩니다.
1. 날짜 형식으로 변환: DateTime(년, 월, 일, 시, 분, 초)
2. 날짜 형식으로 변환: Date(년, 월, 일)
사용자가 날짜로 변환하는
목적은 날짜 계산이나 주(week) 등을 표시하기 위함입니다. 따라서
아래의 날짜 함수도 익혀 두시면 좋습니다. 반대로 날짜에서 숫자나 문자로 변환하는 함수는 아래와 같습니다.
1. yyyy-mm-dd
형식의 문자로 출력: String([날짜])
2. yyyymmdd 형식의 문자로 출력:
SubString(String([날짜]),1,4) & SubString(String([날짜]),6,2) & SubString(String([날짜]),9,2)
3. yyyymmdd
형식의 정수로 출력:
Int(SubString(String([날짜]),1,4) & SubString(String([날짜]),6,2) & SubString(String([날짜]),9,2))
n 날짜 함수 사용하기
날짜 계산은 아래와 같습니다.
1. 오늘 날짜: today()
2. 날짜 차이 계산: DateDiff("day",[앞날짜],[뒷날짜])
3. 요일 계산:
DayOfWeek([날짜]): 숫자로 표기됨, 0: 일/1:월/2:화/3:수/4:목/5:금/6:토
4. 주차 계산: Week([날짜]), 1주: 연도의 최초 일요일까지
/ 2주~ : 월요일~일요일
n 오버(Over) 함수 사용하기
다른 함수들은 다른 프로그램들에서
비슷한 용법으로 사용해봤거나, 설명이 비교적 이해하기 쉽지만, 오버
함수는 생소하기도 하고 바로 이해하기도 어렵습니다. 하지만 알고 있다면 활용도가 높은 함수이기 때문에
알아두면 많은 곳에 써먹을 수 있을 것 입니다. 오버 함수는 집계 함수라고도 합니다. 보통의 함수들은 동일 로우에서 다른 컬럼들을 참조해서 작동하는 경우가 많습니다. 하지만 오버 함수는 전체 데이터 테이블 또는 다른 로우에서 다른 컬럼들을 참조해서 작동합니다. 아래는 오버 함수의 사용 방법입니다.
1. 집계함수([col_name])
OVER(옵션[col_name])

오버 함수 작동 원리
오버 함수는 하나의 로우를
참조하는 것이 아닌 전체 데이터 테이블을 참조하며, 오버 뒤에 나오는 컬럼을 정렬하고 묶어서 사용할
수 있게 해줍니다.

오버 함수 사용 방법
오버 함수의 옵션들은 Over 뒤 컬럼 정렬 및 사용 할 때의 방법을 옵션들로 제공합니다. 예를
들어, Allprevious는 해당 컬럼 정렬 후 해당 내용보다 앞선 내용의 값들만 사용하겠다는 의미입니다. Intersection의 경우 여러 개의 컬럼에 대해 오버 함수를 적용하고 싶을 때 사용합니다.
n 표현식
실제 동작은 표현식에 표시된
내용으로 컬럼을 생성합니다. 따라서 함수를 포함한 모든 수식이나 변수들은 표현식에 표현할 수 있어야
합니다. 표현 방법은 Excel의 수식을 적용하는 것과 동일합니다. 함수를 정해진 문법에 따라 작성하고 필요한 수식과 절차를 적절히 작성하며 됩니다. 이 표현식의 표현은 새 컬럼 계산뿐만 아니라 Spotfire 내의
다양한 기능에서 쓸 수 있습니다.
한편, 표현식에서 컬럼만 표시하는 것과 함수 내에 컬럼을 사용하는 것은 다른 의미를 가집니다. 단순히 [column 이름]의
값은 하나의 로우에서 해당 컬럼에 대한 값을 대변합니다. 함수 내에 컬럼을 사용하는 것은 데이터 테이블
전체에서 구하는 값을 대변합니다. 위의 두 사실이 중요한 것은 정확한 계산 결과를 얻기 위함입니다. 아래의 그림은 전체에 대한 비율을 구하는 표현식입니다. 각 로우의
비율을 구하기 위해서 분자에는 컬럼을 사용하여 각 로우 값이 사용되었고, 분모에는 함수를 사용하여 데이터
테이블 전체 합을 구했습니다.
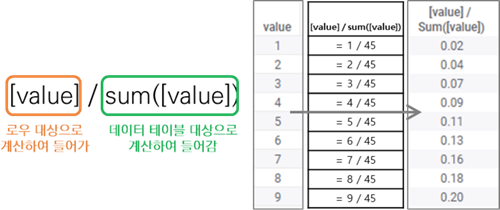
표현식에서의 컬럼과 함수
내 컬럼 사용의 계산 차이
위에서 설명한 계산된 컬럼의
범위는 표현식이 표현할 수 있는 범위가 되고, 그것은 Spotfire에서
제공하는 함수와 다항식과 절차 등으로 제한됩니다. 이외의 복잡한 알고리즘이나 표현 방법은 분석을 통해
좀 더 확장된 내용들을 다룰 수 있습니다.
n 특정 조건을 만족하는 표현식 작성
오버 함수는 특정 컬럼을
대상으로 동일한 조건끼리 모아 계산하였습니다. 표현식과 if 함수를
잘 활용하면 오버 함수와 비슷하게 특정 컬럼의 특정 조건만 모아 계산 할 수 있습니다. 이 표현식은
자주 사용되기 때문에 알아 두시면 좋을 것 같습니다.
1. Avg(If([조건column]조건식, [대상column]))
이 표현식은 조건 컬럼의
조건식을 만족하는 로우에서만 대상 컬럼의 값을 계산합니다.
l 7.5.2. 정규화
정규화(Normalization)는 서로 다른 차원들 간의 스케일을 동일하게 맞춰주는 것 입니다. 대표적인 정규화 방법으로는 통계에서 사용하는 정규분포(Normal
distribution)로 변환하는 정규화(z-score), 또는 최소 값과 최대 값을
활용하는 min-max 정규화, 또는 놈(Norm)을 활용하는 L1 정규화 등이 많이 알려진 방법입니다. Spotfire에서 제공하는 정규화 방법은 14가지이며 활용 방법에
따라 8개로 분류하여 설명 드리겠습니다.
|
종류 |
표현식 |
설명 |
|
평균으로 정규화 |
||
|
normalization by mean |
[대상] / avg([대상]) |
평균으로 나눠주는 방법 |
|
normalization by mean, rescale by baseline mean |
[대상] * avg([참조]) / avg([대상]) |
평균으로 나눠준 후 baseline의 평균을 곱해주는 방법 |
|
normalization by trimmed mean |
[대상] /
trimmedMean([대상], trim값) |
극단 값을 제외한 평균값으로 나눠주는 방법 |
|
normalization by trimmed mean, rescale by baseline
trimmed mean |
[대상] *
trimmedMean([참조], trim값) /
trimmedMean([대상], trim값) |
극단 값을 제외한 평균값으로 나눠준 후 baseline의 평균을
곱해주는 방법 |
|
퍼센트로 정규화 |
||
|
normalization by percentile |
[대상] /
percentile([대상], n) |
하위 n%의 데이터로 나눠주는 방법 |
|
normalization by percentile, rescale by baseline
percentile |
[대상] *
percentile([참조], n) / percentile([대상], n) |
하위 n%의 데이터로 나눠준 후 baseline 의 하위 n%의 데이터를 곱해주는 방법 |
|
[0:-1]로 정규화 |
||
|
scale between 0 and 1 |
([대상]-min([대상])) / /(max([대상])-min([대상])) |
max-min 정규화 방법 |
|
(-)로 정규화 |
||
|
subtract the mean |
[대상] -avg([대상]) |
평균 값을 빼준 값 |
|
subtract the median |
[대상] -med([대상]) |
중간 값을 빼준 값 |
|
[-1:1]로 정규화 |
||
|
normalization by signed ratio |
[대상]>[참조] : [대상]/[참조] [대상]<=[참조] : - [참조]/[대상] |
baseline column과 비교하여 크면
양수, 작으면 음수 |
|
log로 정규화 |
||
|
normalization by log ratio |
log10([대상]/[참조]) |
비율의 log10 값 |
|
normalization by log ratio in standard deviation units |
log10([대상]/[참조]) / std(log10([대상]/[참조])) |
std로 나눈 값 |
|
z-score로 정규화 |
||
|
Z-score calculation |
[대상] - avg([대상]) / sdt([대상]) |
|
|
std로 정규화 |
||
|
normalize by standard deviation |
[대상] / sdt([대상]) |
normalize by standard deviation |
l 7.5.3. 컬럼 계산 및 바꾸기
컬럼 계산 및 바꾸기(Calculated and replace column)은 기존 컬럼의 컬럼 값을 바꿉니다. 기능 실행 시 새 컬럼 계산과 유사한 모습의 윈도우 창이 나타납니다.
위치: 데이터 캔버스 - 데이터 변환 - 컬럼 계산 및 바꾸기

컬럼 계산 및 바꾸기의 설정
창 모습
새 컬럼 계산 과 다른 점은
최상단에 있던 데이터 테이블 선택하는 곳 대신 수정하고 싶은 컬럼을 선택해야 한다는 것 입니다. 또한
바꿀 컬럼 선택 시 아래의 컬럼 이름 칸에는 기본 값으로 바꿀 컬럼 이름이 들어가게 됩니다. 이 칸에서
컬럼 이름을 수정하면 컬럼 이름까지 바뀌게 됩니다. 이외에는 새 컬럼 계산 과 동일하게 컬럼, 프로퍼티, 함수를 사용하여 표현식을 만듭니다.
l 7.5.4. 컬럼 이름 변경
컬럼 이름 변경(Change column names)은 기존에 있는 컬럼 이름을 바꿔 줍니다.
기능 실행 시 데이터 테이블의 컬럼들을 선택하고 새로운 이름을 넣을 수 있는 설정 창이 나타납니다.
위치: 데이터 캔버스 - 데이터 변환 - 컬럼 이름 변경

컬럼 이름 변경의 설정 창
모습
그림과 같이 설정 창 상단에는
이름을 바꿀 컬럼을 선택할 수 있고, 하단에는 새로운 컬럼 이름을 넣을 수 있습니다. 다소 아쉬운 부분은 컬럼 이름 여러 개를 한번에 바꿀 수 없다는 것입니다. 한
번에 컬럼 이름 하나씩 바꿔야 합니다.
l 7.5.5. 데이터 형식 변경
앞서 분석의 데이터(Data in analysis)에서 컬럼 분류(Categorize
column)과 데이터 유형(Data type)을 변경하는 방법을 소개했습니다. 데이터 변환(Data transform)에서도 데이터 형식 변경(Change data types)이 가능합니다. 데이터 변환에서 변경하는
것은 데이터 캔버스를 통한 이력이 남기 때문에 데이터 변환으로 진행하는 걸 추천합니다.
위치: 데이터 캔버스 - 데이터 변환 - 데이터 형식 변경

데이터 형식 변경의 설정
창 모습
데이터 형식 변경은 여러
개의 컬럼들에 대해 유형(Type)과 서식(Formatting)을
한 번에 지정할 수 있습니다. 설정 창의 상단에서 클릭이나 드래그로 컬럼들을 선택할 수 있고, 중앙의 드롭 다운 목록에서 새로운 유형과 서식을 지정할 수 있습니다. 최하단에는
미리보기에서 변경 후 유형과 서식을 확인할 수도 있습니다.
l 7.5.6. 값 바꾸기
값 바꾸기(Replace value)는 하나의 컬럼에서 하나의 값을 바꿀 수 있는 기능입니다. 표에서 값을 변경했던 것과 유사한 설정 창이 뜹니다. 변경할 컬럼을
선택하고, 변경할 값과 새로운 값을 넣으면 값이 변경 됩니다. 하나의
컬럼에서 동일한 값을 가지는 모든 로우 값을 바뀌기 때문에 신중하게 사용해야 합니다. 데이터 변환에서
값 바꾸기로 설정 시, 데이터 캔버스에 이력이 남아 수정, 삭제
등이 편리합니다.
위치: 데이터 캔버스 - 데이터 변환 - 값 바꾸기

값 바꾸기의 설정 창 모습
l 7.5.7. 특정 값 바꾸기
특정 값 바꾸기(Replace specific value)는 하나의 컬럼에서 하나의 값을 바꿀 수 있는 기능입니다. 값 바꾸기(Replace value)와 유사한 기능이지만, 다른 점은 다른 컬럼들로 조건을 부여할 수 있다는 것입니다. 특정
값 바꾸기 실행 시 아래와 같은 설정 창이 나타납니다.
위치: 데이터 캔버스 - 데이터 변환 - 특정 값 바꾸기

특정 값 바꾸기의 설정 창
모습
데이터를 바꾸길 원하는 컬럼을
선택하고, 바꿀 대상의 값을 넣고, 새로운 값을 넣으면 됩니다. 새로운 값을 넣을 때 다른 컬럼을 이용한 조건을 붙일 수도 있습니다. 아래쪽에
행 식별 기준(Identify row by)를 선택하면 바꿀 컬럼 이외의 다른 컬럼을 선택할 수 있고, 선택한 컬럼의 값에 해당하는 로우에서만 바꾸기 기능이 작동 됩니다. 예를
들면 다른 컬럼의 값이 0(또는 empty value, 특정
값)인 로우에서만 컬럼 값을 바꾸게 할 수 있습니다. 바꾸기
변환보다는 새 컬럼 계산이나 컬럼 계산 및 바꾸기 기능을 사용하는 것이 좋습니다. 데이터 변환에서 특정
값 바꾸기로 설정 시, 데이터 캔버스에 이력이 남아 수정이 편리합니다.
l 7.5.8. 컬럼 제외
컬럼 제외(Exclude columns)는 데이터 테이블에서 필요없는 컬럼을 삭제하는 기능입니다. 하지만 이 기능이 필요한 경우는 많지 않습니다. Spotfire에서는
기능 설정이 컬럼 단위로 진행되기 때문에 필요없으면 사용하지 않으면 됩니다. 처음 데이터 테이블을 로드
할 때나, 최종 데이터 테이블을 만들 때 불필요한 컬럼들 삭제하는 경우에만 사용할 수 있습니다. 하지만 컬럼들을 삭제하는 것은 불필요한 경우가 많기 때문에 컬럼 제외 기능을 사용하는 것은 추천하지 않습니다.
위치: 데이터 캔버스 - 데이터 변환 - 컬럼 제외

컬럼 제외의 설정 창 모습
컬럼 제외 실행 시, 남길 컬럼과 삭제할 컬럼으로 나누는 설정 창이 뜹니다. 처음에는
모든 컬럼이 왼쪽 포함(Include) 쪽에 있지만 삭제하고자 하는 컬럼을 가운데 버튼을 통해 오른쪽
제외(Exclude)로 이동하면 됩니다. 설정 창 아래쪽에는
미리보기가 있어 삭제 후 데이터 테이블의 모습을 예상할 수 있습니다.
l 7.5.9. 행 필터링
행 필터링(Filter rows)는 데이터 테이블에서 필요 없는 로우를 삭제하는 기능입니다. Spotfire에서 로우는 데이터를 의미하기 때문에 데이터를 삭제하는 것과 동일합니다. 한편, 컬럼 제외(Exclude
columns)는 사용하지 않으면 차트에 활용될 일이 없지만, 행 필터링은 필터로 제외하지
않는 이상 무조건 반영되기 때문에 삭제가 필요한 경우가 종종 발생합니다.
위치: 데이터 캔버스 - 데이터 변환 - 행 필터링

행 필터링의 설정 창 모습
행 필터링 실행 시, 새 컬럼 생성과 유사한 설정 창이 뜹니다. 차이는 설정창 아래쪽의
새로운 컬럼 이름을 입력하는 칸이나 미리보기, 형식 내용이 없다는 것입니다. 표현식의 결과가 참(True)인 로우는 남기고, 거짓(False)인 로우는 거르는 방식입니다. 따라서 표현식에서는 계산 결과가 참거짓(Boolean) 형식인 결과가
나와야 합니다. 예를 들면, [컬럼] > 0 과 같이 If 문이나
Case when 의 조건문에 들어가는 내용을 입력하시면 됩니다.
l 7.5.10. 피벗
앞선 데이터 테이블 내 변환에서
대부분은 컬럼 또는 로우를 수정하거나 삭제, 생성과 관련된 변환입니다.
하지만 피벗과 언피벗은 하나의 데이터 테이블을 재구성하는 일입니다. 피벗은 데이터 테이블
내의 가지고 있던 정보들을 토대로 일부만을 집계하는 재구성 방법입니다. 엄밀히 말하자면 피벗은 집계
변환이자 차원 확장이자 하위 계층으로 분류하는 변환입니다. 피벗 설정에 따라 다르겠지만, 로우가 많은 표에서, 컬럼 하나를 컬럼 방향으로 폈다고 상상하시면
좋을 것 같습니다. 피벗의 구성요소는 아래와 같습니다.
위치: 데이터 캔버스 - 데이터 변환 - 피벗

피벗의 모습
- 행 지시자(Row
identifiers): 집계 기준입니다. 행 지시자로 선택된 컬럼들을 기준으로 동일한
값을 가지는 로우들을 집계 합니다.
- 컬럼 제목(Column
titles): 2차 집계 기준입니다. 행 지시자 이후에 컬럼 제목으로 선택된 컬럼들을
기준으로 2차적으로 분류하는 집계 기준입니다.
- 값 및 집계 함수(Values
and aggregation method): 집계 대상 컬럼과 집계 함수를 지정할 수 있습니다. 해당
행 지시자, 해당 컬럼 제목으로 분류된 로우들을 셀에 집계해 줍니다.
- 컬럼 및 집계 메서드 전송(Transfer
columns): 위의 구성 요소 이외의 컬럼들을 표시해 줍니다.
위와 같은 구성요소를 가지는
피벗은 아래와 같은 원리로 변환을 진행합니다.

피벗의 원리
l 7.5.11. 언피벗
언피벗(Unpivot)은 정보를 합치는 재구성 방법입니다. 상세히 말하자면, 여러 컬럼들을 두 개의 컬럼(범주 컬럼, 값 컬럼)들로 묶어줍니다. 컬럼이
많은 표에서, 여러 컬럼들을 합쳐서 로우 방향으로 길게 늘어 놓았다고 상상하시면 좋습니다. 언피벗의 구성요소는 아래와 같습니다.

언피벗의 모습
- 통과할 컬럼(Column to
pass though): 그대로 둘 column 입니다.
다음의 변환할 컬럼의 종류 별로 중복되어 값이 들어갑니다.
- 변환할 컬럼(Columns to
transform): 2개의 컬럼으로 합칠 컬럼들 입니다. 몇개의 컬럼을 합치든 최종적으로 2개의 컬럼으로 변환됩니다. 2개의 컬럼은 범주(Category) 컬럼과 값(Value) 컬럼이며, 범주 컬럼에는 선택한 컬럼 이름이 들어가며, 값 컬럼에는 선택한
컬럼들의 값이 들어갑니다.

언피벗의 원리
n 피벗과 언피벗의 관계
이름에서 알 수 있듯이 피벗과 언피벗은 반대되는 변환이며, 앞서 Spotfire와 Excel을 비교할 때 그리고 크로스 테이블을 소개할 때도 언급 되었습니다. 피벗과 언피벗을 한 번씩 진행한 결과를 통해 실제로 반대 변환 임을 확인해 보겠습니다.

피벗과 언피벗의 관계
피벗과 언피벗 진행 후 데이터 테이블이 다시 원래 상태로 돌아온 것을 확인할 수 있습니다. 변환 후에도 3가지 컬럼으로 표현되며, 각 컬럼의 값들은 정확히 일치하지 않습니다. 이것은 피벗 변환에서 집계 함수를 사용하여 데이터가 축약되기 때문이고 이후 언피벗을 사용하더라도 삭제된 정보는 복구되지 않습니다. 또한 결과의 컬럼2, 컬럼3의 이름 정보는 없어지게 됩니다.

![[spotfire] 7. 데이터 처리 ③ - 데이터 테이블 내 변환](https://blogger.googleusercontent.com/img/a/AVvXsEgImP7HJ7E7hEYaQLoHH5rmPEaAMwbWp9jOGlLW1kT_7U3hqt1jG3ibk74w6He3WbwEYpkewrGmZhe6d0WckpeiX_9pG89Fzo93N6f53p4E7Qn38Cz5apECUUP-bT6gNX9MK9fyN3ghR2mMK3cT0IKysWaCiO1rUiWxamn0DUXOnEb_sDhQ-NdDguBM=w100)
![[spotfire] 7. 데이터 처리 ① - 데이터 확인, 필터와 필터링 스키마](https://blogger.googleusercontent.com/img/a/AVvXsEgW_Ids_iTRLRLwzOvwbD9Y1p2cXK351_PGTdf9emqiL8A5ziIA9TuitzqdoQj7u-ovcwFywJxM2-odQStTMRT3e_jA6nB5pVIZSdP9eTh005qZIFNlataZ6VjQAy71cdQo0Jc75IKyEM1tyCLuqikanDqbDsVAMFRwV8MPuUTsciPQcgxwVpjCgPHH=w100)
![[spotfire] 15.1. 막대 그래프 (bar chart)](https://blogger.googleusercontent.com/img/a/AVvXsEhNzfvbH1fgKSffrBJ1DBoeTGwJ8R5Mg8HGzLvM-YCJ2KlPvrJQ6AwZhxAsqEhpOE1HUTIbJa7qFgsbeBimDmm-6Ifa3XDc8CYGVQ_uV2O2-rZtJV_D7ojaaDHHx5-CsMqeVkseoiNQgUghaj__X9Gk2a4Uqw2ZK6fwDcHx3bZ8lgTgjjPjRCIO8Za0=w100)
0 댓글